Breaking down GROMACS Parallel Performance
In this work, we quantified GROMACS parallel performance using different configurations, HPC systems, and FFT libraries (FFTW, Intel MKL FFT, and FFT PACK). We broke down the cost of each GROMACS computational phase and identify non-scalable stages, such as MPI communication during the 3D FFT computation when using a large number of processes. We show that the Particle-Mesh Ewald (PME) phase and the 3D FFT calculation significantly impact the GROMACS performance. We also investigated performance opportunities with a particular interest in developing GROMACS for the FFT calculations.
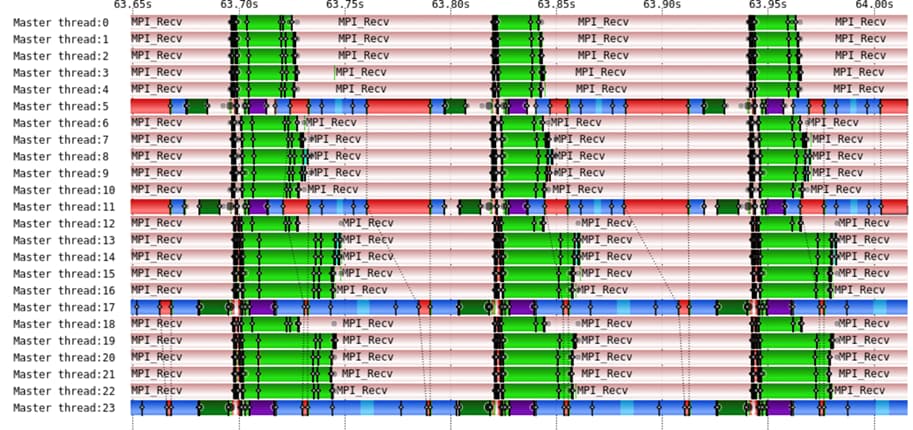
Figure: Tracing of a GROMACS run with 24 processes using ScoreP and Vampir tools. Four processes (three visible) complet the PME calculations.
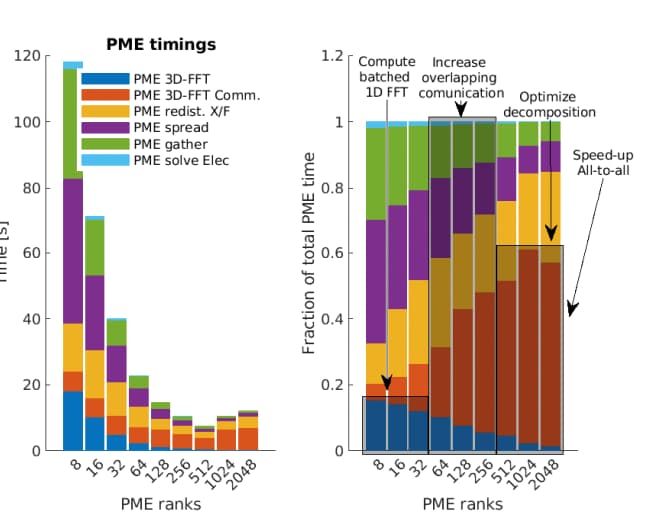
Figure: PME execution time increasing the ranks dedicated to PME Calculations
Reference: Andersson, M.I., Murugan, N.A., Podobas, A. and Markidis, S., 2022. Breaking Down the Parallel Performance of GROMACS, a High-Performance Molecular Dynamics Software. arXiv preprint arXiv:2208.13658. Accepted for publication at 14th International Conference on parallel processing and applied mathematics (PPAM), 2022.


