Assessing the Performance Improvements of new Features in CUDA Unified Memory
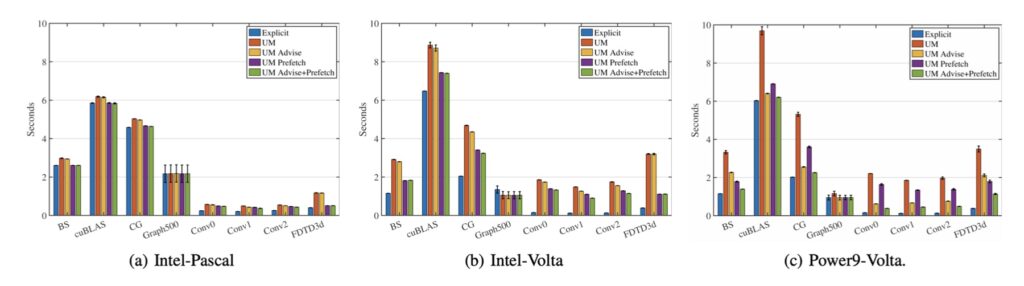
Recently, leadership supercomputers are becoming increasingly heterogeneous. For instance, the two fastest supercomputers in the world, Summit, and Sierra, are both equipped with Nvidia V100 GPUs for accelerating workloads. One major challenge in programming applications on these heterogeneous systems arises from the physically separate memories on the host (CPU) and the device (GPU). Kernel execution on GPU can only access data stored on the device memory. Thus, programmers either need to explicitly manage data using the memory management API in CUDA or relying on programming systems, such as OpenMP 4.5 and RAJA, for generating portable programs. Today, a GPU can have up to 16 GB of memory on top supercomputers while the system memory on the host can reach 256 GB. Leveraging the large CPU memory as a memory extension to the relatively small GPU memory becomes a promising and yet challenging task for enabling large-scale HPC applications. CUDA Unified Memory addresses the challenges as mentioned above by providing a single and consistent logical view of the host and device memories on a system. CUDA has introduced new features for optimizing the data migration on UM, i.e., memory advises and prefetch. Instead of solely relying on page faults, the memory advice feature allows the programmer to provide data access pattern for each memory object so that the runtime can optimize migration decisions. We evaluate the effectiveness of these new memory features on CUDA applications using UM. Due to the absence of benchmarks designed for this purpose, we developed a benchmark suite of six GPU applications using UM. We evaluate the impact of the memory features in both in-memory and oversubscription executions on two platforms. The use of memory advises results in performance improvement only when we oversubscribe the GPU memory on the Intel- Volta/Pascal-PCI-E systems. On Power9-Volta-NVLink based system, using memory advises leads to performance improvement only for in-memory executions.
Reference Publication: Chien, Steven, Ivy Peng, and Stefano Markidis. “Performance Evaluation of Advanced Features in CUDA Unified Memory.” 2019 IEEE/ACM Workshop on Memory Centric High-Performance Computing (MCHPC). IEEE, 2019.
Figure: Performance improvements by using advanced features in CUDA unified memory


